
Posted on maio 6, 2024
VPN de uma Maneira Diferente!
Hoje tivemos um problema aqui na empresa super simples de resolver, mas como não é algo do nosso dia a dia, estávamos fazendo errado. 🙁
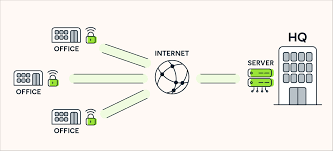
Um dos nossos clientes resolveu mover todo seu ambiente de homologação para trás de um firewall, deixo-o acessível apenas por VPN. Já usávamos VPN para alguns casos específicos, mas dessa vez todo o time alocado nesse cliente teve que começar a trabalhar conectado na VPN.
Como disse, já usávamos VPN, então isso não foi um problema, a questão é que agora tínhamos um time inteiro de quase 10 pessoas penduradas em uma VPN, e como ela estava configurada de forma básica, todo o tráfego das pessoas do time estava sendo roteado pelo nosso servidor de VPN. Nem preciso dizer que em pouco tempo isso se tornou um baita problema, né?
Usamos o OpenVPN como servidor de VPN em uma VM em uma dessas Clouds padrão de hoje em dia, e eles têm limite de tráfego. Logo tínhamos o pessoal do time querendo trabalhar, mas o servidor legado sem conseguir suprir a demanda.
A solução era simples, mas como nunca havíamos passado por isso antes, demoramos um pouco para chegar nela. No fim das contas, conseguimos dizer ao OpenVPN Client, através do arquivo de configuração, quais redes devem ser roteadas por aquela conexão. O nosso problema era que o Cliente estava configurado da forma padrão, e dessa forma ele instala uma rota default no O.S, que roteia todo o tráfego para a conexão da VPN.
Vou te mostrar como fizemos. No arquivo de configuração do cliente, aquele com a extensão .ovpn, você precisa adicionar algumas linhas. A primeira é uma configuração que diz ao OpenVPN para não aceitar mais a rota default.
route-nopull
Depois disso, basta ir adicionando as redes que devem ser roteadas através da VPN com o comando abaixo.
route 61.58.180.0 255.255.255.0
Na linha acima, você tem que adicionar o IP da sua aplicação e a máscara de rede. Se a aplicação tiver apenas um IP a máscara ficaria 255.255.255.252, o equivalente a um /32. Você pode adicionar quantas linhas forem necessárias.
Bem, era isso! Não falei que era fácil? 😉
Posted on abril 30, 2024
O Declínio dos Consoles
Um dia desses, eu estava assitindo um vídeo sobre as dificuldades de se desenvolver jogos para o Playstation 2 e como o hardware dele é poderoso. Esse é um assunto que sempre me encantou: Como funcionam os consoles ao nível de hardware e suas peculiaridades.
Sempre fiquei entusiasmado em me aprofundar nas diferenças de design, nas particularidades, saber mais da história, dos porquês e comos.
Mas de repente me veio à mente: Como estragamos o mercado de games para console!
Eu explico. Antigamente era bem comum termos certas dificuldades para desenvolver jogos por conta das restrições de capacidade do hardware, como pouca memória, pouco armazenamento, processador “lento”, e assim vai. Mas além dos problemas normais, também havia as particularidades de cada console, como o fato dos jogos para Super Nintendo serem escritos em Assembly, ou mesmo da arquitetura diferenciada do PS 2, ou do processador de determinado console se MIPS do concorrente se PowerPC, e na minha opinião essas dificuldades e idiossincrasias é que davam graça a coisa, ai que estava a magia!
O desenvolvedor tinha que estudar a fundo o console, saber de todos os detalhes e funções escondidas, e muitas vezes encontrar soluções para seus problemas que não estavam na documentação oficial, isso fazia com que tivessemos grandes jogos lançados, com recursos que muitas vezes nem se acreditava ser possível para a época, conseguíamos tirar água de pedra. Era divertido jogar, mas também era divertido criar os jogos.

Mas hoje em dia isso mudou, os consoles são como meros PCs com processadores velozes, placas de vídeo “top” e muita memória RAM. Hoje temos duas ou três engines que dominam o mercado e ditam as regras do que é possível ou não ser feito, e se quisermos implementar algo muito fora da caixa, muitas vezes temos que esperar pelo recurso ser disponibilizado pela engine que estivermos usando.
Por falar em engine, hoje em dia se tornou comum o desenvolvimento de jogos “low code”. Arrasta um componente daqui, coloca uma animação padrão ali, dar play em um som na hora certa, pega uns assets padrões do site xyz e pronto, o jogo está pronto e possível de ser lançado para PC, WI, PS 5, Xbox, Android, Iphone e até para a sanduicheira da sua cozinha!
Sou só eu ou você também acha que isso está fácil demais? Chato demais?
Vejá bem, não estou dizendo que todo jogo hoje em dia é feito dessa forma, ou mesmo que se fizemos um jogo “low code” ele será ruim. E nem digo que não fizemos grandes avanços na qualidade de alguns títulos. Temos recursos de realismo surpreendentes.
Mas cadê o desafio? Cadê o diferencial?
Antigamente era comum termos disputas entre amigos de quem tinha o melhor console, discutíamos porque a arquitetura X era melhor que Z. Hoje em dia, nem sei se vale mais a pena ter um console ou simplesmente compra um PC Gamer e pronto.
Posted on abril 29, 2024
Oracle Cloud e Pouca Memória
Já tem muito tempo que a OCI(Oracle Cloud Infrastructure) existe, e a tempos ela oferece alguns recursos “grátis” para teste.
Já de início, não gostei da usabilidade deles, recursos de difícil configuração e documentação difícil de encontrar parece ser um padrão por lá. Mas é “grátis”!
Já havia feito alguns testes no passado, mas nunca passou disso. Até que tive a idéia de voltar bloggar!
Então a idéia foi a de subir uma infra básica para o wordpress lá na OCI, como eu queria testar melhor a capacidade deles decidi subir um Portainer e dois cointainers docker, um para o WordPress e outro para o MariaDB. Para quem estiver querendo fazer o mesmo, aqui está a documentação oficial, mas depois de alguns testes aqui está o docker composer que utilizei:
version: '3.1'
services:
mariadb:
image: mariadb:latest
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: wordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
image: wordpress:latest
links:
- mariadb:mysql
volumes:
- wp_data:/var/www
- wp_php:/usr/local/etc/php
- wp_apache:/etc/apache2
ports:
- 3080:80
restart: always
environment:
WORDPRESS_DB_HOST: mariadb:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
volumes:
db_data:
external: true
wp_data:
external: true
wp_php:
external: true
wp_apache:
external: true
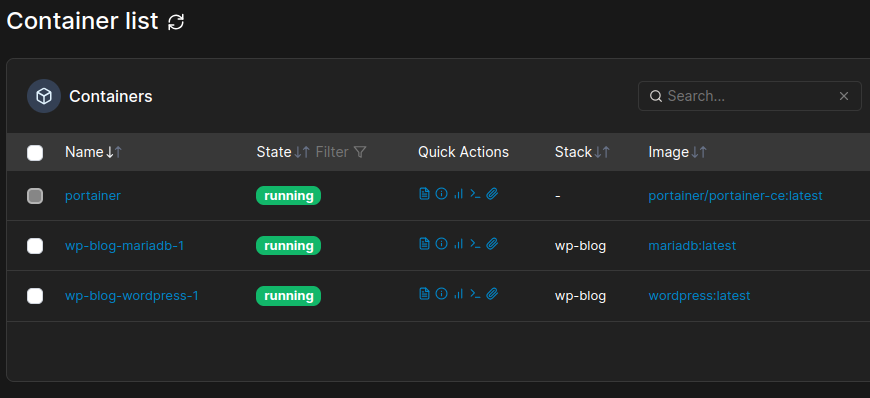
Bom, depois disso tudo configurado eu decidi usar a Cloudflare como proxy para não deixar o servidor diretamente exposto, então usei o Cloudflare Tunnel – Zero Trust App Connector para servir de proxy/firewall. Mais para frente trago um post detalhando o processo de configuração, mas já adianto que é super fácil.
Com isso tudo configurado, agora é hora de instalar um tema legal e começar a postar… Mas pera!
Para os desavisados a instancia “grátis” da OCI é bem… bem básica, 1 core de processador com 2 threads , 1Giga de RAM e 0.48Giga de rede, isso mesmo, menos de 500 Mega de velocidade, mas para um simples blog pensei ser o suficiente. Estava enganado!

Logo começaram os travamentos com a vm ficando sem memória, o pior é que a instalação padrão do Ubuntu na OCI não vem nem com Swap configurada. Então vamos configurar.
sudo fallocate -l 1G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
sudo cp /etc/fstab /etc/fstab.bak
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
Caso você ainda tenha problemas com o consumo de memória na sua instância, existe a opção de desinstalar o Oracle Agent, isso vai te poupar facilmente 200MB de memória
sudo snap remove oracle-cloud-agent
Agora sim, tudo funcionando como deve, só falta postar com frequência (parte mais difícil)!
Bom, só para resumir, se você está aqui lendo esse post agora é porque a OCI funciona. 😉
Posted on abril 28, 2024
Tokenization
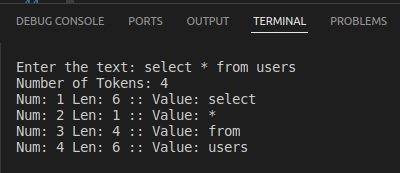
Recentemente um amigo me fez um pequeno desafio, criar um programa em C que tivesse como entrada uma string(frase) e fizesse split dos espaços transformando cada palavra em um token, no final printar a quantidade de token encontrados e todos os tokens em sequência com seu respectivo tamanho.
Um dos requisitos principais é que os tokens sejam armazenados em uma array de tamanho dinamico.
E o codigo acabou ficando assim:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX_LENGTH 1024
typedef struct {
char **tokens;
int size;
} Splited;
void initSplited(Splited *splited) {
splited->tokens = malloc(0);
splited->size = 0;
}
void freeSplited(Splited *splited) {
for (int i = 0; i < splited->size; i++) {
free(splited->tokens[i]);
}
free(splited->tokens);
}
void split(char *str, char *delim, Splited *splited) {
char *tokens = strtok(str, delim);
while(tokens != NULL) {
splited->tokens = (char **)realloc(splited->tokens, (splited->size + 1) * sizeof(char *));
if (splited->tokens == NULL) {
printf("Memory allocation failed\n");
exit(1);
}
splited->tokens[splited->size] = (char *)malloc(strlen(tokens) + 1);
if (splited->tokens[splited->size] == NULL) {
printf("Memory allocation failed\n");
exit(1);
}
strcpy(splited->tokens[splited->size], tokens);
splited->size++;
tokens = strtok(NULL, delim);
}
}
int main() {
char buffer[MAX_LENGTH];
Splited splited;
initSplited(&splited);
printf("Enter the text: ");
fgets(buffer, MAX_LENGTH, stdin);
split(buffer, " ", &splited);
printf("Number of Tokens: %d\n", splited.size);
for (int i = 0; i < splited.size; i++) {
printf("Num: %d Len: %zu :: Value: %s\n", i + 1, strlen(splited.tokens[i])* sizeof(char), splited.tokens[i]);
}
freeSplited(&splited);
return 0;
}
Como tem muito tempo que não leio nem escrevo nada em C, provavelmente tem muito a ser melhorado, mas o importante é que funcionou. 🙂
Caso tenha alguma idéia para melhorar o código, pode deixar aqui nos comentários!